25 Nov Crawl-delay
Il crawl delay è un comando (che va digitato come segue: crawl-delay) che può essere inserito nel file Robots.txt. Ha il compito di comunicare ai crawler dei motori di ricerca di rallentare la loro azione di scansione al fine di non sovraccaricare i server, evitando così di rallentare il funzionamento del sito.
1. Di cosa stiamo parlando? Il senso di crawl-delay: 10
Prima di entrare nel merito, forse è il caso di fare un po’ di contesto per chi non è assolutamente avvezzo al lessico SEO. Poniamo che tu abbia un sito che usi per vendere scarpe nell’area metropolitana di Milano. Se un utente cerca su Google o su un altro motore di ricerca una serie di parole come “vendita scarpe online Milano”, il tuo obiettivo è di finire fra i primi risultati di quella ricerca. Per far sì che ciò avvenga, il tuo sito deve come minimo essere indicizzato nel grande database di Google, e l’indicizzazione avviene grazie a una serie di software (i crawler o spider) che periodicamente lo vengono a “controllare”, passando da un link all’altro e analizzando pagine nuove e vecchie per capire se ci sono aggiornamenti.
Grazie ai crawler, quindi, il tuo sito può essere indicizzato, soprattutto se dispone di un file Robots.txt scritto correttamente. Il file Robots.txt ti permette di guidare crawler e spider a scansionare o ignorare determinate pagine così da agevolarne il lavoro.
Oltre a questo, possiamo istruire questi bot a fare o non fare altre operazioni, e una di queste è proprio quella di crawl-delay, ovvero di scansionare più lentamente l’intero sito onde evitare sovraccarichi nel server.
La stringa esatta da inserire nel file Robots.txt è:
crawl-delay: 10
che tradotto in linguaggio macchina significa ‘fra una scansione e quella successiva devono passare almeno 10 secondi’. È questo un ottimo stratagemma per evitare che i motori di ricerca anziché agevolare la fluidità del sito ne compromettano la navigabilità, ma attenzione: non tutti rispettano il comando. Vediamo nel dettaglio quali.
2. Come Google e gli altri motori di ricerca interpretano il crawl delay?
Bing e Yahoo riconoscono il comando crawl-delay. Quindi se scrivi nel Robots.txt la stringa crawl-delay: 10, questi due motori di ricerca divideranno il giorno in tranche da 10 secondi, e fra una tranche e quella successiva scansioneranno una sola pagina.
Anche Yandex, motore di ricerca fondamentale se aspiri a ritagliarti una fetta di mercato in Russia, aspetterà 10 secondi prima di passare da un link all’altro. Tuttavia, nonostante il comando venga supportato, gli sviluppatori suggeriscono di usare la piattaforma Yandex Webmaster per modificare la velocità di crawling.
Baidu, necessario per approcciare al ricchissimo mercato cinese, non riconosce il comando crawl-delay, ma permettere di gestire la frequenza di crawling tramite gli strumenti del Baidu Webmaster.
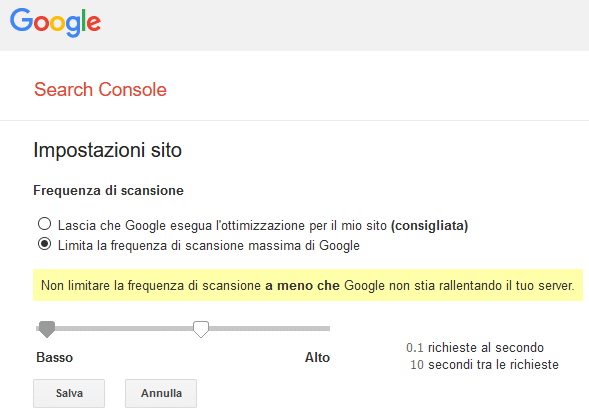
Infine, va segnalato che neanche Google riconosce il comando, quindi i suoi crawler si limiteranno a ignorarlo. Se vuoi che Google scansioni più lentamente, devi impostare il limite di scansione (o crawl rate) all’interno della Google Search Console. Per farlo, collegati alla Google Search Console e recati sulla pagina delle impostazioni di scansione (per comodità, puoi raggiungerla direttamente da questo link). Clicca poi sull’opzione “limita la frequenza di scansione massima di Google” e a quel punto, muovendo la freccetta presente in basso, potrai impostare il tempo che ritieni più congruo debba passare fra una scansione e quella successiva (vedi esempio in basso).